Впечатления от семинара по нагруженным системам
 Не так давно мне посчастливилось побывать на одном очень увлекательном мероприятии — на семинаре Андрея Смирнова по разработке надёжных высоконагруженных систем. Семинар длился три дня — 4,5,6 июля — и проходил в учебном центре «Школа Олега Бунина». В семинаре участвовало 18 человек, никто из них не пожалел выходных, и это того стоило! Андрей Смирнов прекрасно знает свое дело и не жалеет своих знаний для слушателей.
Не так давно мне посчастливилось побывать на одном очень увлекательном мероприятии — на семинаре Андрея Смирнова по разработке надёжных высоконагруженных систем. Семинар длился три дня — 4,5,6 июля — и проходил в учебном центре «Школа Олега Бунина». В семинаре участвовало 18 человек, никто из них не пожалел выходных, и это того стоило! Андрей Смирнов прекрасно знает свое дело и не жалеет своих знаний для слушателей.
Изложенный на семинаре материал даёт представление об устройстве современных нагруженных систем, об алгоритмах и технологиях, которые в этой области используются, о проблемах достижения надёжности. В конечном итоге становится понятно, что к чему, паззл складывается ;)
 Основной принцип, который я для себя выделил: в общем виде задача не решается. Например, если мы создаём социальную сеть, то в общем случае (достижимом только теоретически) любой пользователь может зафрендить/заfollow’ить любого пользователя. В этом случае объём данных, необходимых для хранения «связей» будет слишком быстро расти с ростом числа пользователей. В реальной жизни такого не происходит, поэтому каждая подобная система — это грамотно продуманный частный случай, вводящий/использующий ограничения и обладающий способностью к масштабированию.
Основной принцип, который я для себя выделил: в общем виде задача не решается. Например, если мы создаём социальную сеть, то в общем случае (достижимом только теоретически) любой пользователь может зафрендить/заfollow’ить любого пользователя. В этом случае объём данных, необходимых для хранения «связей» будет слишком быстро расти с ростом числа пользователей. В реальной жизни такого не происходит, поэтому каждая подобная система — это грамотно продуманный частный случай, вводящий/использующий ограничения и обладающий способностью к масштабированию.
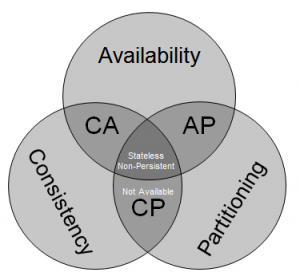 Очень порадовала CAP-теорема. Тем, что невозможность создания идеальной системы (с согласованными данными C, полной доступностью A и устойчивостью к разделению P одновременно) доказана математически: могут выполняться только 2 из 3. Действие этой теоремы было проиллюстрировано в ходе семинара: были рассмотрены несколько типов возможных систем (CA, AP, CP). Вот бы увидеть математическое доказательство правила «быстро, качественно, дёшево — выберите любые два» :)
Очень порадовала CAP-теорема. Тем, что невозможность создания идеальной системы (с согласованными данными C, полной доступностью A и устойчивостью к разделению P одновременно) доказана математически: могут выполняться только 2 из 3. Действие этой теоремы было проиллюстрировано в ходе семинара: были рассмотрены несколько типов возможных систем (CA, AP, CP). Вот бы увидеть математическое доказательство правила «быстро, качественно, дёшево — выберите любые два» :)
 Андрей уделил большое внимание хранилищам «ключ-значение», подходу NoSQL, и рассмотрел несколько популярных приложений, таких как memcached, redis, mongoDB. Мне кажется, что нам стоит задействовать что-нибудь подобное в MX-RTP для ускорения генерации отчётов: отчёты генерируются только за определённый интервал времени (скажем, последние сутки). Более того, пользуясь полученными знаниями надо пересмотреть архитектуру системы и усовершенствовать её, ведь нет пределов совершенству :)
Андрей уделил большое внимание хранилищам «ключ-значение», подходу NoSQL, и рассмотрел несколько популярных приложений, таких как memcached, redis, mongoDB. Мне кажется, что нам стоит задействовать что-нибудь подобное в MX-RTP для ускорения генерации отчётов: отчёты генерируются только за определённый интервал времени (скажем, последние сутки). Более того, пользуясь полученными знаниями надо пересмотреть архитектуру системы и усовершенствовать её, ведь нет пределов совершенству :)
Поскольку речь шла о надёжных системах, были рассмотрены способы репликации и конкретные примеры распределённых баз данных, таких как riak, cassandra. В-общем, очень интересно было открыть для себя новый мир :) Очень интересно было узнать про шардирование, т.е. предсказуемое распределение данных по разным хранилищам.
Пересказывать всё не имеет смысла (было более 700 слайдов!), лучше сходить на семинар и послушать самостоятельно. Чуть не забыл — были и практические упражнения, не только теория. Все рассмотренные приложения — это open source решения, поэтому попробовать можно любое абсолютно бесплатно.
PS: Послушав семинар, я понял, что наши разработки имеют прямое отношение к направлению HighLoad, ведь мы умеем обрабатывать потоки данных на битрейтах 10 и 100 гигабит в секунду без потерь. А система мониторинга MX-RTP наблюдает за десятками тысяч камер в режиме 365/24/7.
Поэтому я предложил на суд программного комитета конференции HighLoad++ тему для доклада: Использование ПЛИС(FPGA) для распределения вычислительной нагрузки при обработке сетевых пакетов на 100% linerate». В этом докладе я хочу на примере системы Беркут-MX/RTP показать, как, используя ПЛИС, можно на порядки снизить нагрузку на сервер, собирающий статистику, и таким образом, обработать десятки (и даже сотни) гигабит трафика.
Я правильно понимаю, что вы в данном случае рассматриваете решение аналогичное http://www.gigamon.com ?
Да, правильно, у gigamon есть похожие решения.
Я планирую рассмотреть решение просто как пример, а бОльший упор сделать на технологию обработки пакетов в ПЛИС/ASIC, проанализировать распределение нагрузки.
Там на доклад даётся пятьдесят минут, придётся конкретно потрудиться ;) Но это даже хорошо, так как за 10 минут я вряд ли смогу объяснить суть обработки пакетов в ПЛИС/ASIC.